Los 10 comandos de Linux que uso cada día como DevOps

Nivel: intermedio🎯
⏱ 8 min de lectura
Cuando empecé en DevOps pensaba que necesitaba memorizarme cientos de comandos. La realidad es que el 80% del trabajo diario se resuelve con un conjunto pequeño y bien dominado. Aquí te cuento los que realmente uso, con ejemplos reales y contexto de producción.
📚Índice
- grep en Linux: cómo filtrar logs en producción
- tail -f: monitorizar logs en tiempo real en Linux
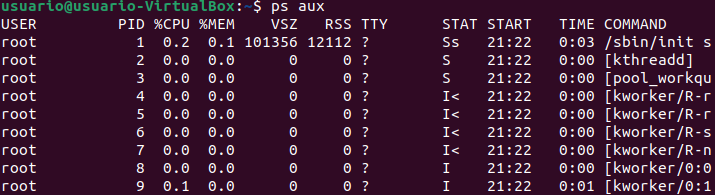
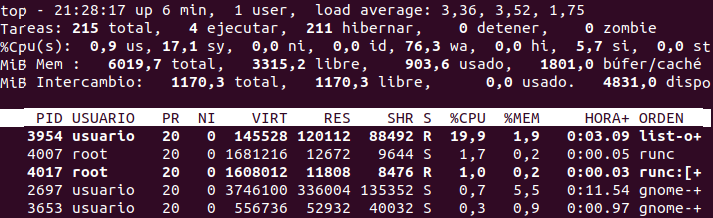
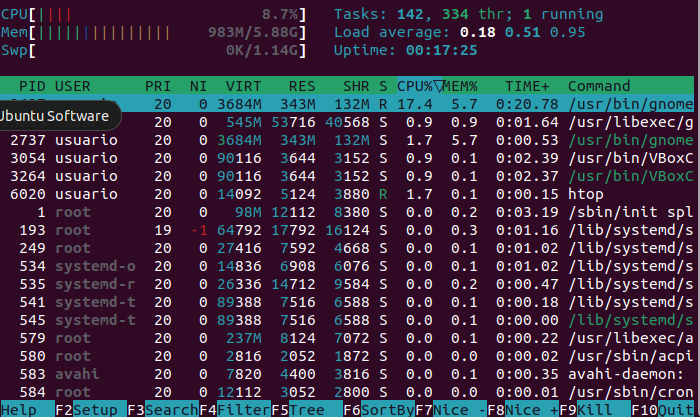
- ps, top y htop: ver qué está consumiendo el servidor
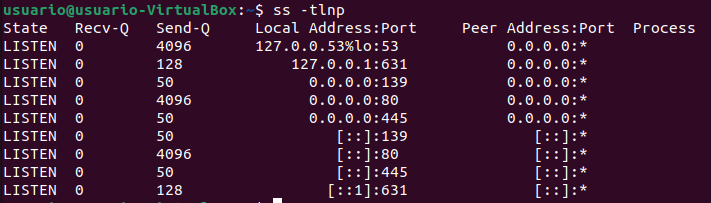
- ss y netstat: ver conexiones de red activas en Linux
- curl en Linux: probar APIs y endpoints sin salir de la terminal
- rsync: copiar,comprimir,backups
- find en Linux: localizar archivos y limpiar disco
- awk: procesar y filtrar texto en la terminal Linux
- systemctl: gestionar servicios Linux con systemd
- jq: parsear y filtrar JSON desde la terminal Linux
1. grep en Linux: cómo filtrar logs en producción
Si existe un comando en Linux que te salve de más de una, ese es grep.Filtra miles de lineas de logs para encontrar el error exacto, esto es una habilidad clave, por eso lo uso a diario.
$ grep -i "error" /var/log/nginx/error.log
$ grep -r "timeout" /var/log/app/
$ grep -E "ERROR|WARN" app.log | grep "2026-04"
2026-04-07 14:32:11 ERROR connection timeout to db:54322. tail -f: monitorizar logs en tiempo real en Linux
Cuando hay un incidente activo necesito ver los logs mientras suceden. tail -f hace exactamente eso. Lo tengo casi siempre abierto en producción combinado con grep.
$ tail -f /var/log/syslog
$ tail -f /var/log/app.log | grep --line-buffered "ERROR"
# Ver las últimas 100 líneas primero, luego seguir en vivo
$ tail -n 100 -f /var/log/nginx/access.log3. ps, top y htop: ver qué está consumiendo el servidorps,top y htop: ver qué está consumiendo el servidor
Cuando un servidor va lento o un proceso se dispara, necesitas saber qué está pasando y quién lo está causando. Para eso tienes tres herramientas complementarias — cada una sirve para una situación distinta:
-
ps: Lista los procesos que están corriendo en este momento
-
top: Vista en tiempo real que se actualiza cada segundo. Muestra los procesos ordenados por consumo de CPU
-
htop: Como top pero con colores, barras de CPU por núcleo y navegación con teclado
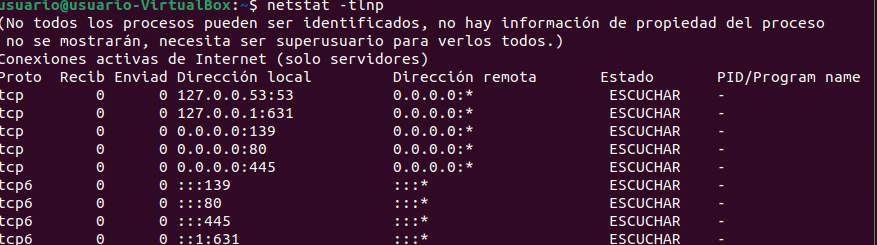
4. ss y netstat: ver conexiones de red activas en Linux
¿Está el puerto 8080 abierto? ¿Quién está conectado a la base de datos? Estas preguntas tienen respuesta en segundos. ss es el sucesor moderno de netstat y viene preinstalado en la mayoría de distros actuales.

5. curl en Linux: probar APIs y endpoints sin salir de la terminal
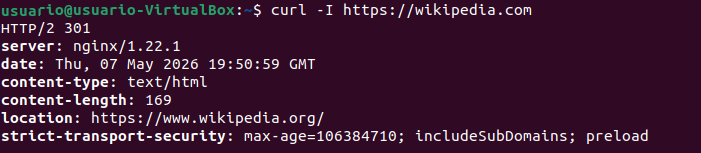
Sin abrir Postman, sin interfaz gráfica. curl es imprescindible para verificar que una API responde correctamente, especialmente cuando estás dentro de un servidor remoto o en un pipeline CI/CD.
(Ver solo cabeceras HTTP)
#Comprobar si API responde
$ curl -X POST -H "Content-Type: application/json" \
-d '{"user":"test"}' https://api.ejemplo.com/login-v para modo verbose. Verás la negociación TLS, headers de request y response — perfecto para depurar problemas de HTTPS y seguridad web.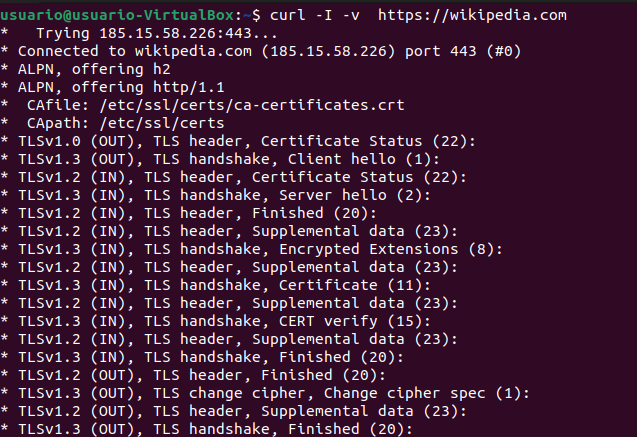
6. rsync: copiar,comprimir,backups
Piensa en rsync como un copiar y pegar inteligente. A diferencia de cp, que copia todo siempre, rsync solo transfiere lo que ha cambiado. Si tienes 1.000 archivos y modificas 3, rsync mueve solo esos 3.
Hagamos un ejemplo.
Queremos hacer una copia de la carpeta de mis proyectos (ubicada en el escritorio) en un HDD externo el cual esta montado en una carpeta en el escritorio.

La segunda ve3z que ejecutemos el comando, si no hay ninguna modificacion o archivo nuevo obtendremos la siguiente salida en pantalla.

7. find en Linux: localizar archivos y limpiar disco
Archivos grandes que llenan el disco, ficheros modificados en las últimas horas, configuraciones mal ubicadas... find los localiza todos. Uno de los comandos Linux más subestimados.
$ find /var/log -name "*.log" -mtime +30 -delete
# Elimina logs de más de 30 días
$ find / -size +100M -type f 2>/dev/null
# Archivos mayores de 100MB8. awk: procesar y filtrar texto en la terminal Linux
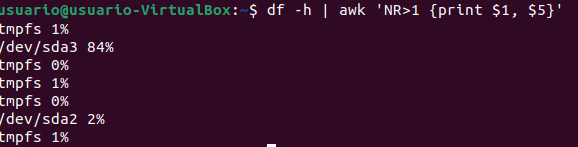
No hace falta dominar awk al 100% para sacarle valor. Con 3 patrones básicos resuelves el 90% de los casos: extraer columnas, filtrar filas y sumar valores de logs o métricas.
Disco y porcentaje de uso (omitiendo cabecera)
9. systemctl: gestionar servicios Linux con systemd
En entornos con systemd (la mayoría de distros modernas), systemctl es el punto de control de todos los servicios. Lo uso constantemente con nginx, docker, postgres y cualquier daemon del sistema.
$ systemctl status nginx
$ systemctl restart docker
$ systemctl enable postgresql
10. jq: parsear y filtrar JSON desde la terminal Linux
En un mundo de APIs y microservicios, procesar JSON en la terminal es una habilidad crítica. jq hace lo que awk hace con texto plano, pero para JSON estructurado.
$ curl -s https://api.ejemplo.com/users | jq '.[] | .name'
"Ana García"
"Carlos Ruiz"
$ cat config.json | jq '.database.host'
"db.produccion.internal"
$ kubectl get pods -o json | jq '.items[].metadata.name'Conclusión
Dominar estos comandos Linux para DevOps no te hace experto en Linux de golpe, pero sí te da una base sólida para moverte con confianza en entornos de producción. El truco no es memorizar flags: es entender cuándo usar cada herramienta y combinarlas con tuberías (|).
La terminal es el lenguaje nativo del DevOps. Cuanto antes te sientas cómodo en ella, más rápido crecerás en este campo. Si quieres profundizar, en zymeralabs.com tienes más guías técnicas sobre Linux, Docker y backend.
grep. La capacidad de filtrar logs en producción de forma rápida y precisa es la habilidad que más impacto tiene en el día a día de un DevOps. Combínalo con tail -f y tienes una herramienta de diagnóstico muy potente para incidentes en tiempo real.
ss es la elección correcta en 2026. netstat pertenece al paquete net-tools, que está obsoleto y no viene instalado por defecto en las distribuciones modernas. ss es más rápido, más preciso y ofrece más información. La sintaxis es muy similar, así que el cambio es inmediato.
tail -f /ruta/archivo.log. Para servicios gestionados por systemd usa journalctl -u nombre-servicio -f. Si quieres filtrar por un término concreto, añade | grep --line-buffered "término" al final.
man comando o comando --help. Con el tiempo los más usados se quedan solos. Empieza por dominar grep, tail y systemctl.



